网络爬虫
网络爬虫:通过编程语言,获取网页的html代码,通过分析代码获取需要的内容,这种操作为爬取网页内容,通过一些种子URL爬行扩充到整个Web,网路爬虫就像一只蜘蛛一样爬行在自己的网中。这里通过一个案例,爬取分析网络数据:
需求:爬取虎扑网有关罗马队的帖子信息:
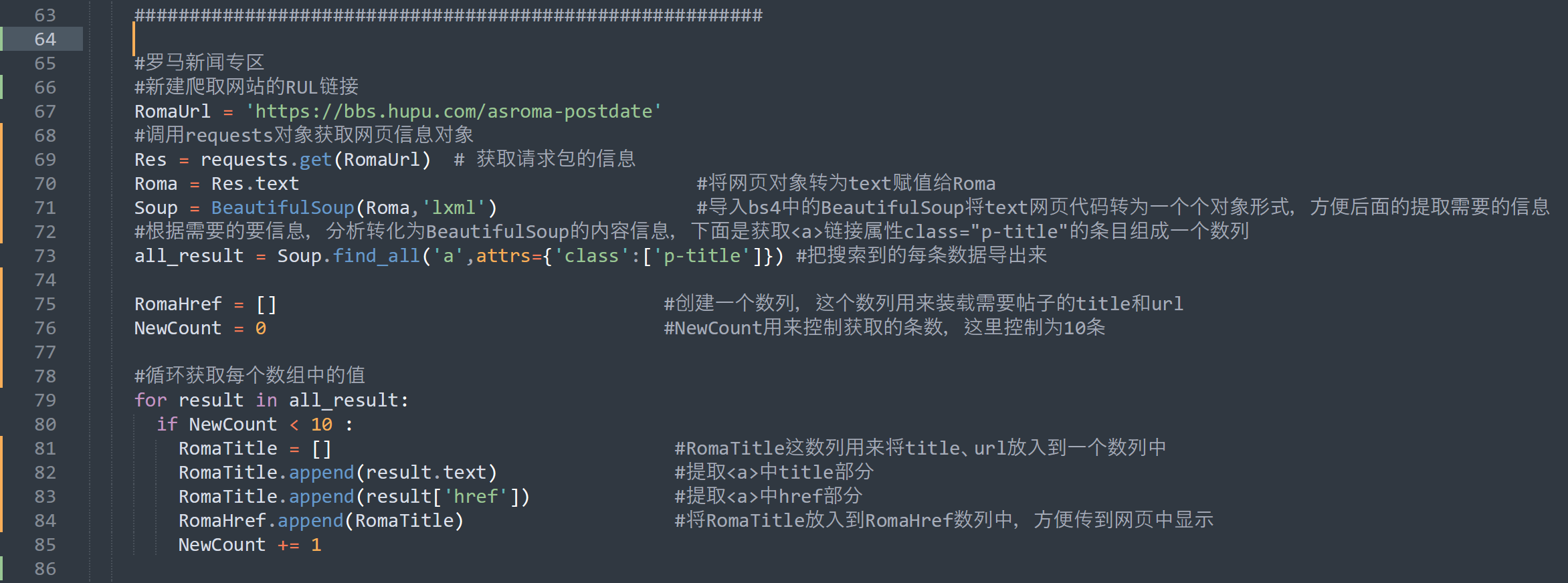
###########################代码区##############################
#罗马新闻专区
#新建爬取网站的RUL链接
RomaUrl = 'https://bbs.hupu.com/asroma-postdate'
#调用requests对象获取网页信息对象
Res = requests.get(RomaUrl) # 获取请求包的信息
Roma = Res.text #将网页对象转为text赋值给Roma
Soup = BeautifulSoup(Roma,'lxml') #导入bs4中的BeautifulSoup将text网页代码转为一个个对象形式,方便后面的提取需要的信息
#根据需要的要信息,分析转化为BeautifulSoup的内容信息,下面是获取a链接属性class="p-title"的条目组成一个数列
all_result = Soup.find_all('a',attrs={'class':['p-title']}) #把搜索到的每条数据导出来
RomaHref = [] #创建一个数列,这个数列用来装载需要帖子的title和url
NewCount = 0 #NewCount用来控制获取的条数,这里控制为10条
#循环获取每个数组中的值
for result in all_result:
if NewCount < 10 :
RomaTitle = [] #RomaTitle这数列用来将title、url放入到一个数列中
RomaTitle.append(result.text) #提取a中title部分
RomaTitle.append(result['href']) #提取a中href部分
RomaHref.append(RomaTitle) #将RomaTitle放入到RomaHref数列中,方便传到网页中显示
NewCount += 1
##############################代码区End################################
##############################Pycharm运行结果###########################
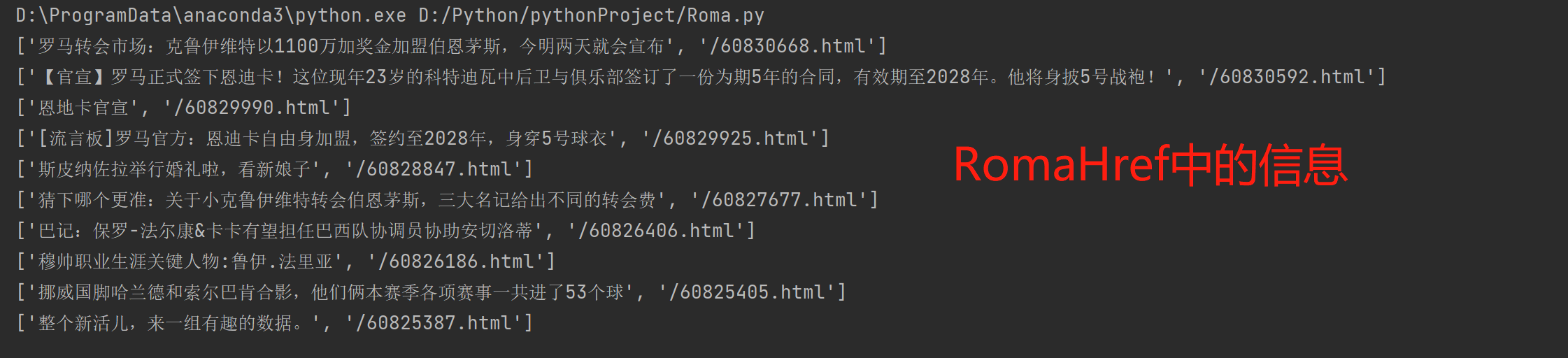
这是网络抓取的一个例子,通过例子可以发散,将网页中的链接存到url数列中,再爬取这些数列中的url,循环下去就可以爬取整个web,当然算法很复杂,需要花时间研究;